AI 智能体(Agent)要落地,最难的往往不是“能不能跑”,而是“能不能稳定地为业务创造价值”。下面这份模板,专为跨团队协作设计:产品、工程、数据、安全、运营可以在同一张需求页上对齐。
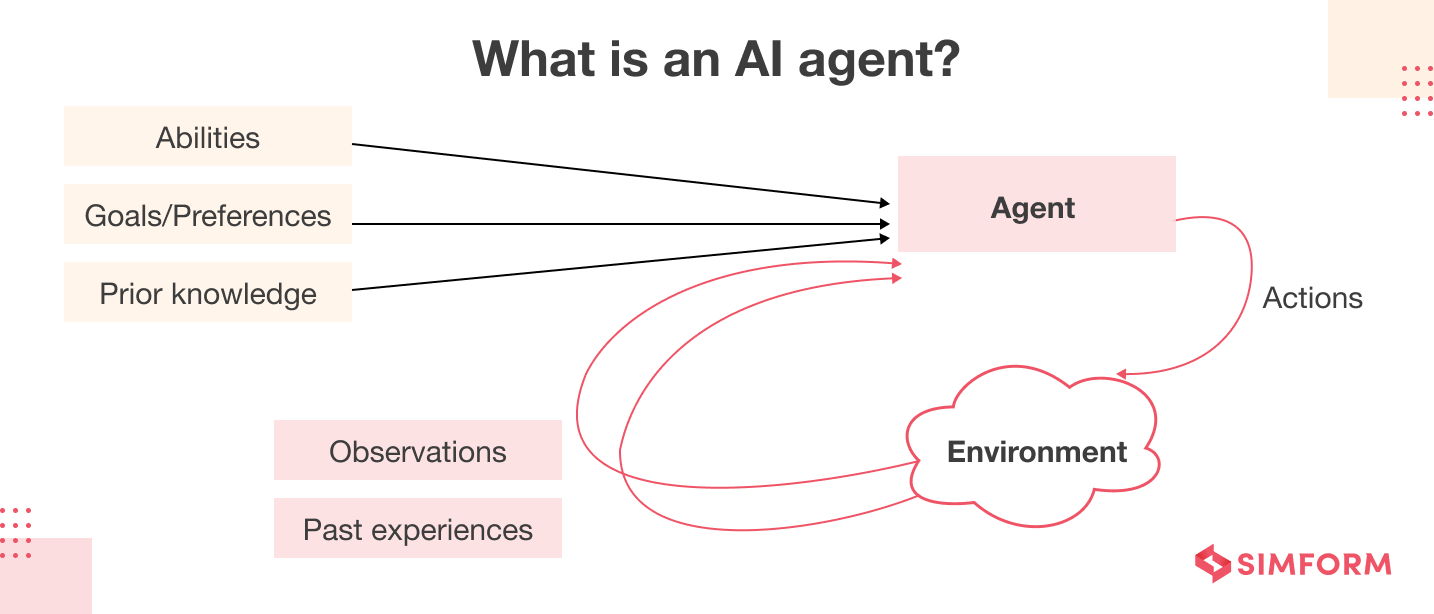
1. 背景与目标(Why/What)
先把“愿景”翻译成“可度量的结果”。
1.1 业务背景
- 触发场景(用户何时需要它)
- 现状痛点(为什么非做不可)
- 关键约束(合规/延迟/成本/可审计)
1.2 产品目标(建议三条以内)
- 目标 1:提升效率(例如:平均处理时长下降 30%)
- 目标 2:提升质量(例如:一次解决率提升到 70%)
- 目标 3:降低风险(例如:不当回答率低于 0.5%)
2. 用户与使用边界(Who/When/Where)
智能体的边界决定了体验与成本。
2.1 主要用户
- 主用户:谁会日常使用
- 管理/运营:谁负责配置、监控与回滚
2.2 运行边界(强烈建议写清楚)
- 能做的事:可调用的工具(Tool)
- 不能做的事:禁止的动作(比如交易、删除、越权访问)
- 需要人工兜底的条件(低置信度、敏感内容、关键决策等)
3. Agent 行为蓝图(How)
用一张“可读的生命周期图”把系统结构对齐(不是实现细节)。
graph TD
U[User request] --> P[Policy gate]
P --> M[Memory & context assembly]
M --> D[Decision & planning]
D --> T[Tool execution]
T --> V[Validation & safety checks]
V --> R[Response synthesis]
R --> O[Observability logs]
3.1 Policy Gate(策略门)
回答前先判断“能不能做”:是否越权、是否敏感、是否需要澄清问题。
3.2 Memory(记忆)
区分三层通常能显著降低幻觉:
- Identity profile:角色画像与风格边界(长期)
- Knowledge base:检索到的事实与引用(外部)
- Session memory:当前对话的短期上下文(短期)
3.3 Decision & Planning(规划)
把“要做什么”显式化:下一步行动是什么、需要哪些工具、成功标准是什么。
4. 工具(Tools)与数据合约(Contract)
很多项目失败于“模型知道怎么说,但不知道怎么拿数据”。工具必须定义清楚输入输出契约。
下面给一个可复用的工具契约表结构(工程可以直接落到接口定义)。
| Tool | Input schema (concept) | Output schema (concept) | Failure mode |
|---|---|---|---|
| SearchKB | query, filters | passages, citations | empty result |
| SQLQuery | sql, params | rows, metadata | timeout |
| TicketCreate | title, description | ticket_id | permission denied |
4.1 Contract 示例(可直接复制)
下面是一段“概念 schema”(你可以替换字段名成你项目的实际类型):
{
"tool": "SearchKB",
"input": {
"query": "如何做Agent评测?",
"filters": {
"kb_version": "2025.10.1",
"tags": ["AI", "Evals"]
}
},
"output": {
"passages": [
{ "id": "kb_chunk_1024", "text": "..." }
],
"citations": [
{ "chunk_id": "kb_chunk_1024", "span": [0, 32] }
]
}
}
5. 质量与验收(How do we know it works?)
验收不要只写“效果不错”,而要写“可回归、可监控、可追溯”。
5.1 离线验收(Offline Evals)
- 题库规模:最少覆盖 100-300 个真实问题变体
- 指标建议:
- task_success_rate(任务成功率)
- groundedness(基于引用的可靠性)
- refusal_rate(应拒绝的比例)
- regression(旧问题回归)
5.2 在线验收(Online Monitoring)
- 关键监控项:
- 工具调用成功率
- 平均延迟 P50/P95
- 安全告警命中率
- 抽样复审:
- 每周对随机样本做人工标注
- 对“高影响场景”做定向抽查
5.3 兜底与回滚(Fallback & Rollback)
- 置信度低:触发追问或转人工
- 工具不可用:走降级策略(只回答通用知识)
- 结果可疑:触发二次验证(例如检索重跑)
6. 交付物清单(Deliverables)
建议需求页至少包含下面这些“可交付资产”,项目会更顺。
- PRD 文档(本页)
- 题库与评测脚本(Offline test set)
- 工具契约表(Tools & Contracts)
- 监控指标字典(Observability spec)
- 失败回路策略(Fallback playbook)
7. 你可以直接套用的“验收清单”
最后给一份可复制的 checklist:
- 覆盖关键场景(至少 10 个主场景)
- 每个场景都有成功标准(可量化)
- 有拒绝/兜底策略(且可测试)
- 每个工具有输入输出契约与失败模式
- 有离线评测集与回归策略
- 有在线监控与抽样复审机制
7.1 验收项到评测的映射(加速对齐)
把“验收项”明确映射到“评测数据/指标”,可以减少团队沟通成本:
graph LR
A[Acceptance: success criteria] --> B[Offline eval set]
A --> C[Online monitoring events]
B --> D[Metrics: task_success / groundedness]
C --> E[Alert triggers: validation_fail / tool_timeout]
模板写到这份上,剩下的是按场景填肉:客服、内容生成、运营助手、游戏内生成,验收侧重点各不相同,但骨架可以共用——目标可量化、工具有契约、失败有退路、线上能回放。 以后若真要落成表单或示例 PRD,也是在这张骨架上长出来,而不是另起炉灶。